机架感知(副本放置策略)
官网地址:
Rack Awareness
HDFS Architecture
一个hadoop分布式集群会有很多的服务器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,机架内的服务器之间的网络速度通常都会高于跨机架服务器之间的网络速度,并且机架之间服务器的网络通信通常受到上层交换机间网络带宽的限制。
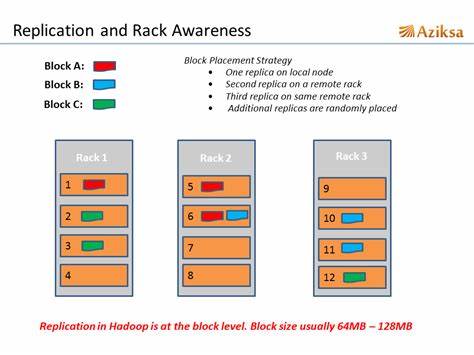
HDFS对数据文件是分block存储,每个block默认有3个副本(也可以配置大于3),HDFS对副本的存放策略如下:
- 第一个副本:放置在Client所在的DN节点上(如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的DN节点)
- 第二个副本:放置在与第一个副本不同的机架的节点上(随机选择)
- 第三个副本:与第二个副本相同机架的不同节点上
- 如果还有更多的副本,随机放在集群的节点中
这样的策略主要是为了数据的可靠性和数据访问的性能:
- 数据分布在不同的机架上,就算当前机架挂掉,其他机架上还有冗余备份,整个集群依然能对外服务。
- 数据分布在不同的机架上,运行MR任务时可以就近获取所需的数据。
块大小和副本数
块大小和副本数需要在hdfs-site.xml中配置。
官网中的相应的默认参数如下:

可以看到,默认块大小为128M,默认副本数为3.
这里会有一个常规的面试题:
问:假如一个文件300M,块128M,副本2。请问实际存储空间多大,多少块?
答:300 x 2 = 600M,3 x 2 = 6块
需要注意的是,实际存储空间=文件大小x副本数,并不是块大小,即使44M也占用一个块。
HDFS小文件问题
HDFS上每个文件都要在NameNode上建立一个索引,这样当小文件比较多的时候,就会产生很多的索引文件,一方面会大量占用NameNode的内存空间,另一方面就是索引文件过大使得索引速度变慢。
小文件的危害:
- HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放的文件数目过多的话会占用很大的内存甚至撑爆内存。
- HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入大量的小文件会花费很长的时间。
- 流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
小文件优化
小文件的优化无非以下几种方式:
- 在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
- 在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
根据上面的思想,可以考虑采用下面的解决方案:
- Hadoop Archive:
是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样就减少了namenode的内存使用。
- Sequence file:
sequence file由一系列的二进制key/value组成,如果key为文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
- CombineFileInputFormat:
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
- 开启JVM重用:
对于大量小文件job,可以开启JVM重用,会减少45%运行时间。
JVM重用理解:一个map运行一个jvm,重用的话,在一个map在jvm上运行完毕后,jvm继续运行其他map。
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
总的来说,解决小文件问题主要就是将小文件合并成大文件,一般约定:尽量使得合并后的大文件<=blocksize,比如110M(假如块大小128M)。
一般在生产上会设置一个阈值,比如10M,作为小文件的门槛,并使用shell脚本调用程序进行小文件的定期合并。
小文件合并脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| package com.practice.spark
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.internal.Logging
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object miniFileMerge extends Logging {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().master("local[2]").appName(this.getClass.getSimpleName).getOrCreate()
val target = "hdfs://fushuaidate:9000/practice/minifilemerge"
val output = new Path(target)
val hdfs: FileSystem = output.getFileSystem(sparkSession.sparkContext.hadoopConfiguration)
val partitions = makeCoalesce(hdfs, output, 5)
println(s"合并后文件数量为:$partitions")
val paths: List[String] = getPaths(hdfs, output)
val mergeFiles: RDD[String] = sparkSession.sparkContext.textFile(target).coalesce(partitions)
val dataFrame = rddToDF(sparkSession, mergeFiles)
dataFrame.write.text(s"$target/.TMP")
val resStatus = hdfs.listStatus(new Path(s"$target/.TMP"))
resStatus.foreach(x => {
if (x.getLen > 0) {
hdfs.rename(x.getPath, output)
}
})
println(s"merge ${paths.size} files => $partitions files")
hdfs.delete(new Path(s"$target/.TMP"), true)
paths.foreach(x => {
hdfs.delete(new Path(x), true)
})
}
def makeCoalesce(fs: FileSystem, path: Path, size: Int): Int = {
var num = 0L
fs.listStatus(path).foreach(x => {
num += x.getLen
})
val partitions = (num / 1024 / 1024 / size).toInt + 1
logInfo("分区数为:" + partitions)
partitions
}
def getPaths(fs: FileSystem, path: Path): List[String] = {
var paths: List[String] = List.empty
fs.listStatus(path).foreach(x => {
x.getLen
x.getPath
paths :+= x.getPath.toString
println(x.getLen + "|" + x.getPath)
})
paths
}
def rddToDF(sparkSession: SparkSession, rdd: RDD[String]): DataFrame = {
import sparkSession.implicits._
val infoDF = rdd.map(x => {
val splits = x.split("\t")
val date = splits(0).trim
val ip = splits(1).trim
val domain = splits(6).trim
date + "\t" + ip + "\t" + domain
}).toDF()
infoDF
}
}
|
本地调试修改owner