SparkStreaming 进阶
目录
- 黑名单管理
- 窗口
- 闭包
- SS对接Kafka
- KafkaRDD
黑名单管理
Spark Streaming在计算流式数据时,有时候需要过滤一些数据,比如一些特殊的字段,或者利用爬虫爬取数据的恶意ip,又或者那些帮助某些无良商家刷广告的人,那么我们有一个黑名单,来过滤或者禁止他们的访问
思路:
- 准备一个管理黑名单的文件,读进RDD作为key,并添加一个value值为true
- Spark Streaming接收流式数据,使用transform转换为RDD,拿到key用来做join,value为数据内容
- 两个RDD做left join,并过滤掉value值为true的数据
1 | def main(args: Array[String]): Unit = { |
SparkStreaming窗口
Spark Streaming还提供了窗口计算功能,允许在数据的滑动窗口上应用转换操作。下图说明了滑动窗口的工作方式:
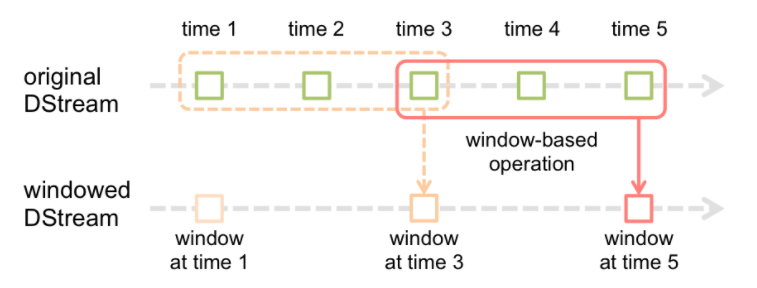
如图所示,每当窗口滑过originalDStream时,落在窗口内的源RDD被组合并被执行操作以产生windowedDStream的RDD。
在上面的例子中,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。
这表明任何窗口操作都需要指定两个参数:
- 窗口长度(windowlength) 窗口的时间长度(上图的示例中为:3)。
- 滑动间隔(slidinginterval) 两次相邻的窗口操作的间隔(即每次滑动的时间长度)(上图示例中为:2)。
这两个参数必须是源DStream的批间隔的倍数(上图示例中为:1)。
我们以一个例子来说明窗口操作。
对之前的单词计数的示例进行扩展,每10秒钟对过去30秒的数据进行wordcount。
为此,我们必须在最近30秒的pairs DStream数据中对(word, 1)键值对应用reduceByKey操作。
这是通过使用reduceByKeyAndWindow操作完成的。
1 | // 执行wordcount |
一些常见的窗口操作如下表所示。所有这些操作都用到了上述两个参数:windowLength和slideInterval。
window(windowLength, slideInterval)
基于源DStream产生的窗口化的批数据计算一个新的DStreamcountByWindow(windowLength, slideInterval)
返回流中元素的一个滑动窗口数reduceByWindow(func, windowLength, slideInterval)
返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数必须是相关联的以使计算能够正确的并行计算。reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每一个key的值均由给定的reduce函数聚集起来。
注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。你可以用numTasks参数设置不同的任务数reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
上述reduceByKeyAndWindow()的更高效的版本,其中使用前一窗口的reduce计算结果递增地计算每个窗口的reduce值。
这是通过对进入滑动窗口的新数据进行reduce操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。
一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。
但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数invFunc)。
像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。请注意,使用此操作必须启用检查点。countByValueAndWindow(windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。
每个key的值都是它们在滑动窗口中出现的频率。
闭包
Spark的难点之一是理解跨集群执行代码时变量和方法的范围和生命周期。在范围之外修改变量的RDD操作可能经常引起混淆。在下面的示例中,我们将查看使用foreach()递增计数器的代码,但是其他操作也可能出现类似的问题。
1 | var counter = 0 |
上述代码的行为是未定义的,可能无法按预期工作。为了执行作业,Spark将RDD操作的处理分解为tasks,每个任务由executor执行。在执行之前,Spark计算task的闭包。闭包是那些executor在RDD上执行其计算时必须可见的变量和方法(在本例中为foreach())。这个闭包被序列化并发送给每个executor 。
闭包中发送给每个executor 的变量现在都是副本,因此,当在foreach函数中引用counter时,它不再是driver 上的计数器。在executors的内存中仍然有一个计数器,但它对executor不再可见!executor只看到来自序列化闭包的副本。因此,counter的最终值仍然是零,因为counter上的所有操作都引用了序列化闭包中的值。
一般来说,像循环或局部定义方法这样的闭包结构不应该用来改变全局状态。Spark不保证闭包外部引用的对象的突变行为。一些这样做的代码可能在本地模式下工作,但那只是偶然的,而且这样的代码在分布式模式下不会像预期的那样工作。如果需要全局聚合,则使用Accumulator。
SparkStreaming对接Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
SS是Spark上的一个流式处理框架,可以面向海量数据实现高吞吐量、高容错的实时计算。SS支持多种类型数据源,包括Kafka、Flume、twitter、zeroMQ、Kinesis以及TCP sockets等。SS实时接收数据流,并按照一定的时间间隔将连续的数据流拆分成一批批离散的数据集;然后应用诸如map、reduce、join和window等丰富的API进行复杂的数据处理;最后提交给Spark引擎进行运算,得到批量结果数据,因此其也被称为准实时处理系统。而结果也能保存在很多地方,如HDFS,数据库等。另外SS也能和MLlib(机器学习)以及GraphX(图计算)完美融合。
下面我们就来一个SS对接Kafka的案例
Kafka Product API
1 | def main(args: Array[String]): Unit = { |
Spark Streaming Consumer
1 | def main(args: Array[String]): Unit = { |
现在,无论在哪里写进Kafka的数据,都可以从Spark Streaming的客户端写出来,我们这里保存的是Redis,保存在MySQL是同样的思路。
KafkaRDD
最后我们看一下如何在代码中拿到Kafka的Offset
1 | def main(args: Array[String]): Unit = { |
注意:
- 对HasOffsetRanges的类型转换只有在对createDirectStream的结果调用的第一个方法中完成时才会成功,而不是在随后的方法链中。
- RDD分区和Kafka分区之间的一一映射会在RDD发生shuffle或者repartition操作之后改变,比如reduceByKey或window