0%
实现多目录输出自定义类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
class MyMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any] {
override def generateActualKey(key: Any, value: Any): Any = NullWritable.get()
override def generateActualValue(key: Any, value: Any): Any = {
value.asInstanceOf[String]
}
override def generateFileNameForKeyValue(key: Any, value: Any, name: String): String = {
s"$key/$name"
}
}
|
主类,使用saveAsHadoopFile(path, keyClass, valueClass, fm.runtimeClass.asInstanceOf[Class[F]])方法保存数据,指定参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| object MultipleDirectory {
def main(args: Array[String]): Unit = {
val out = "spark-core/out"
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
CheckHDFSOutPath.ifExistsDeletePath(sc.hadoopConfiguration,out)
val lines = sc.textFile("spark-core/ip/access-result/*")
val mapRDD: RDD[(String, String)] = lines.map(line => {
val words = line.split(",")
(words(12), line)
})
mapRDD.saveAsHadoopFile(out,
classOf[String],
classOf[String],
classOf[MyMultipleTextOutputFormat])
sc.stop()
}
}
|
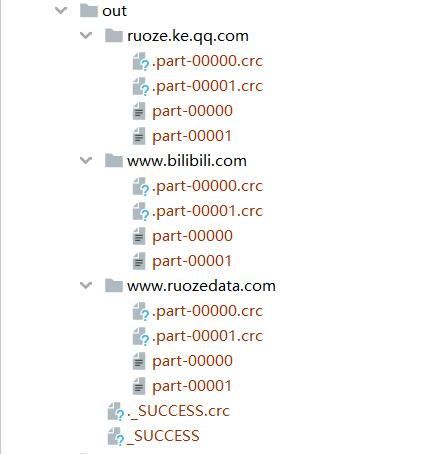
结果