Spark 广播变量
为什么要将变量定义成广播变量?
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
广播变量图解
错误的,不使用广播变量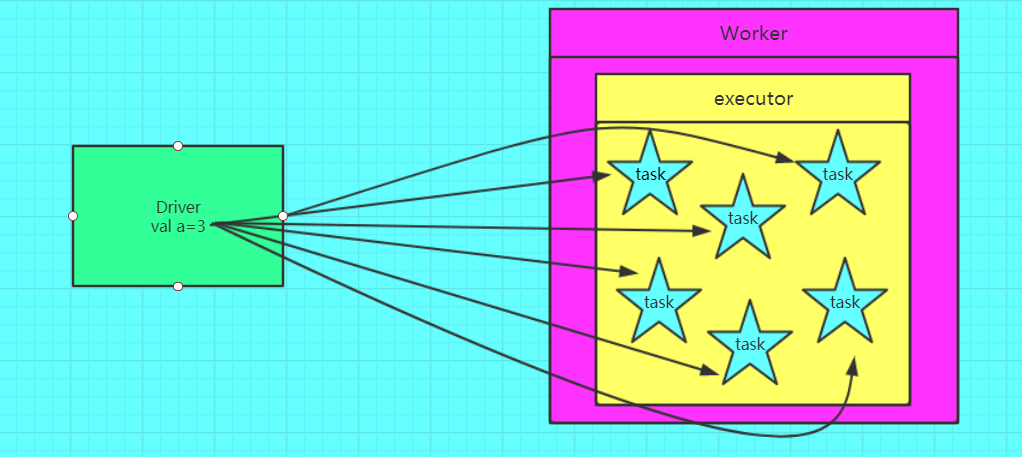
正确的,使用广播变量的情况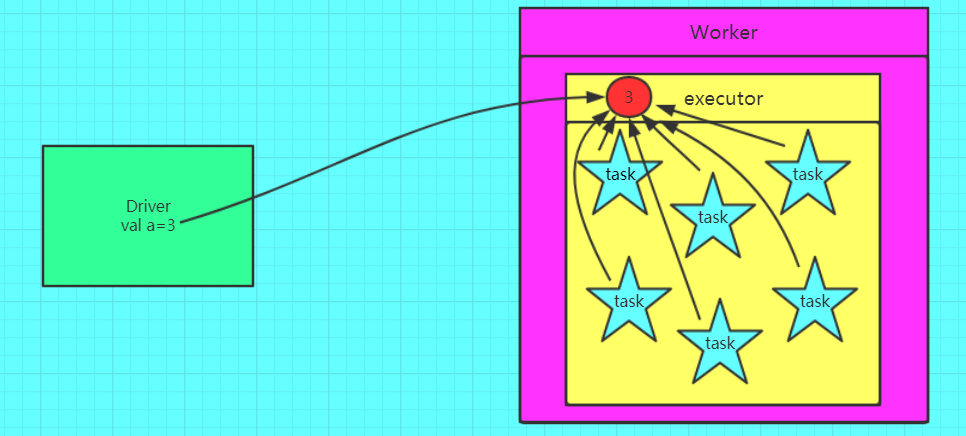
小表广播案例
使用广播变量的场景很多, 我们都知道spark 一种常见的优化方式就是小表广播, 使用 map join 来代替 reduce join, 我们通过把小的数据集广播到各个节点上,节省了一次特别 expensive 的 shuffle 操作。
比如driver 上有一张数据量很小的表, 其他节点上的task 都需要 lookup 这张表, 那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了。
Fact table 航线(起点机场, 终点机场, 航空公司, 起飞时间)
1
2
3
4
5SEA,JFK,DL,7:00
SFO,LAX,AA,7:05
SFO,JFK,VX,7:05
JFK,LAX,DL,7:10
LAX,SEA,DL,7:10Dimension table 机场(简称, 全称, 城市, 所处城市简称)
1
2
3
4JFK,John F. Kennedy International Airport,New York,NY
LAX,Los Angeles International Airport,Los Angeles,CA
SEA,Seattle-Tacoma International Airport,Seattle,WA
SFO,San Francisco International Airport,San Francisco,CADimension table 航空公司(简称,全称)
1
2
3AA,American Airlines
DL,Delta Airlines
VX,Virgin America思路:将机场维度表和航空公司维度表进行广播,生成Map,航线事实表从广播变量中通过key拿到value(计算在每个executor上)
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46object BroadcastApp {
def main(args: Array[String]): Unit = {
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
// Fact table 航线(起点机场, 终点机场, 航空公司, 起飞时间)
val flights = sc.textFile("tunan-spark-core/broadcast/flights.txt")
// Dimension table 机场(简称, 全称, 城市, 所处城市简称)
val airports: RDD[String] = sc.textFile("tunan-spark-core/broadcast/airports.txt")
// Dimension table 航空公司(简称,全称)
val airlines = sc.textFile("tunan-spark-core/broadcast/airlines.txt")
/**
* 最终统计结果:
* 出发城市 终点城市 航空公司名称 起飞时间
* Seattle New York Delta Airlines 7:00
* San Francisco Los Angeles American Airlines 7:05
* San Francisco New York Virgin America 7:05
* New York Los Angeles Delta Airlines 7:10
* Los Angeles Seattle Delta Airlines 7:10
*/
//广播Dimension Table airport,生成Map
val airportsBC = sc.broadcast(airports.map(x => {
val words = x.split(",")
(words(0), words(2))
}).collectAsMap())
//广播Dimension Table airlines,生成Map
val airlinesBC = sc.broadcast(airlines.map(x => {
val words = x.split(",")
(words(0), words(1))
}).collectAsMap())
//通过key获取value
flights.map(lines => {
val words = lines.split(",")
val a = airportsBC.value.get(words(0)).get
val b = airportsBC.value.get(words(1)).get
val c = airlinesBC.value.get(words(2)).get
a+" "+b+" "+c+" "+words(3)
}).foreach(println)
sc.stop()
}
}结果
1
2
3
4
5New York Los Angeles Delta Airlines 7:10
Los Angeles Seattl Delta Airlines 7:10
Seattle New York Delta Airlines 7:00
San Francisco Los Angeles American Airlines 7:05
San Francisco New York Virgin America 7:05
为什么只能 broadcast 只读的变量
这就涉及一致性的问题,如果变量可以被更新,那么一旦变量被某个节点更新,其他节点要不要一块更新?如果多个节点同时在更新,更新顺序是什么?怎么做同步? 仔细想一下, 每个都很头疼, spark 目前就索性搞成了只读的。 因为分布式强一致性。
注意事项
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
能不能将一个RDD使用广播变量广播出去?因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
如果executor端用到了Driver的变量,不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
如果Executor端用到了Driver的变量,使用广播变量在每个Executor中只有一份Driver端的变量副本。