为什么要定义计数器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
图解计数器
错误的图解
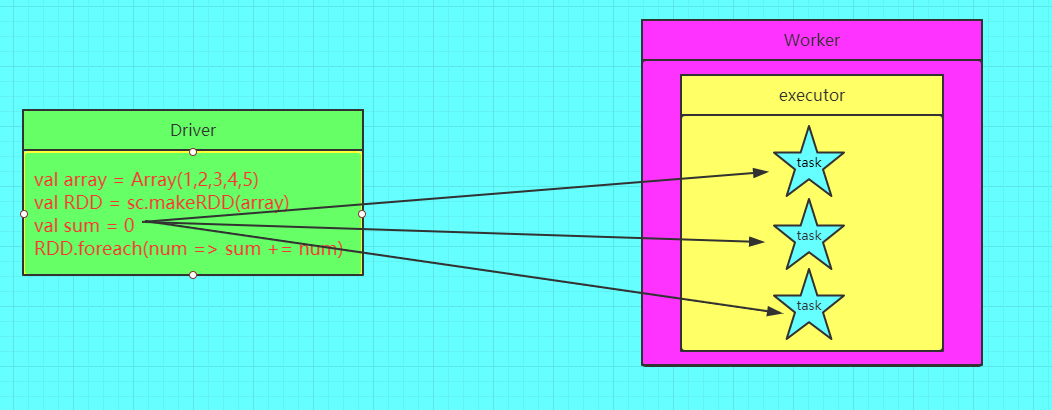
正确的图解
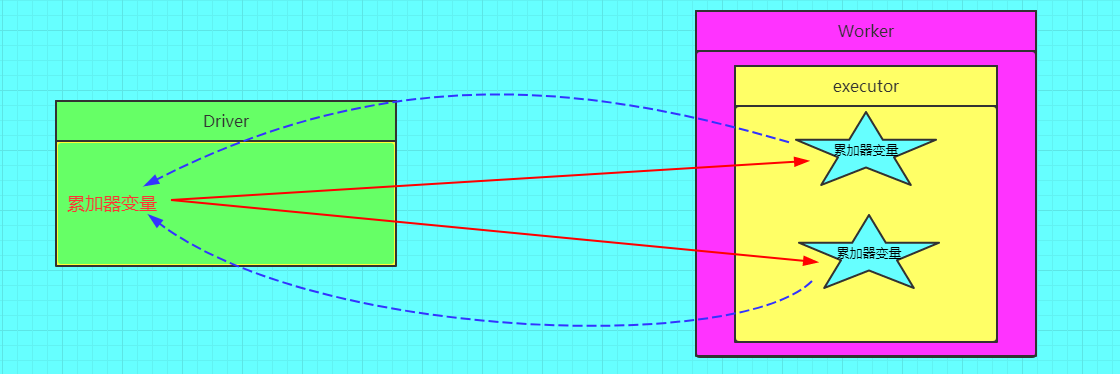
计数器种类很多,但是经常用的就是两种,longAccumulator和collectionAccumulator
需要注意的是计数器是lazy的,只有触发action才会进行计数,在不持久化的情况下重复触发action,计数器会重复累加
LongAccumulator
Accumulators 是只能通过associative和commutative操作“added”的变量,因此可以有效地并行支持。它们可用于实现计数器(如MapReduce)和Spark本身支持数字类型的累加器,程序员还可以添加对新类型的支持。
longAccumulator通过累加的方式计数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| object MyLongAccumulator {
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
var acc = sc.longAccumulator("计数")
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
val forRDD = rdd.map(x => {
acc.add(1L)
})
forRDD.count()
println(acc.value)
}
}
|
使用longAccumulator做计数的时候要小心重复执行action导致的acc.value的变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| object MyLongAccumulatorV2{
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val acc = sc.longAccumulator("计数")
val rdd = sc.parallelize(1 to 8)
val forRDD = rdd.map(x => {
acc.add(1L)
})
forRDD.count()
println(acc.value)
forRDD.count()
println(acc.value)
}
}
|
由于重复执行了count(),累加器的数量成倍增长,解决这种错误累加也很简单,就是在count之前调用forRDD的cache方法(或persist),这样在count后数据集就会被缓存下来,reduce操作就会读取缓存的数据集,而无需从头开始计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| object MyLongAccumulator {
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val acc = sc.longAccumulator("计数")
val rdd = sc.parallelize(1 to 8)
val forRDD = rdd.map(x => {
acc.add(1L)
})
forRDD.cache().count()
println(acc.value)
forRDD.count()
println(acc.value)
}
}
|
CollectionAccumulator
collectionAccumulator,集合计数器,计数器中保存的是集合元素,通过泛型指定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
object MyCollectionAccumulator {
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val acc = sc.collectionAccumulator[People]("集合计数器")
val rdd: RDD[People] = sc.parallelize(Array(People("tunan", 100000), People("xiaoqi", 100001), People("张三", 100222), People("李四", 100003)))
rdd.map(x => {
val id2 = x.id.toString.reverse
if (id2(0) == id2(1) && id2(0) ==id2(2)){
acc.add(x)
}
}).count()
println(acc.value)
}
case class People(name:String,id:Long);
}
|
注意事项:
计数器在Driver端定义赋初始值,计数器只能在Driver端读取最后的值,在Excutor端更新。
计数器不是一个调优的操作,因为如果不这样做,结果是错的