Hive 基本概念 Hive的部署 Hive的常用命令
Hive基本概念
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
什么是Hive
Hive由Facebook开源,用于解决海量结构化日志的数据统计问题。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文化映射为一张表,并提供类SQL查询功能。
本质:将HQL/SQL转化成MapReduce程序
- Hive处理的数据存储在HDFS
- Hive底层执行引擎:MapReduce/Tez/Spark,只需要通过一个参数就能够切换底层的执行引擎
- Hive作业提交到YARN上运行
Hive的优缺点
优点:
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免了MapReduce编程,减少学习成本
- Hive的执行延迟比较高,因此Hive常用于离线分析,对实时性要求不高的场合
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
- Hive的HQL表达能力有限
- 迭代式算法无法表达
- 数据挖掘方面不擅长
- Hive的效率比较低
- Hive自动生成的MapReduce作业,通常不够智能化
- Hive调优比较困难,粒度较粗
Hive的架构原理
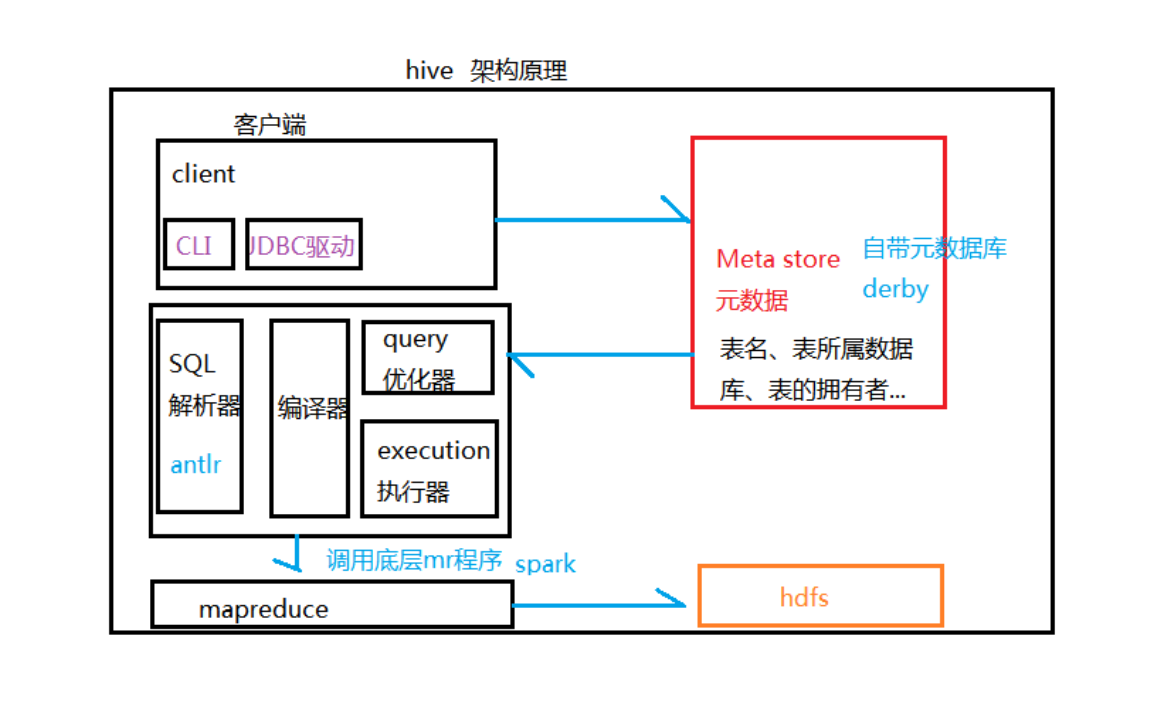
如上图所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后将执行返回的结果输出到用户交互接口。
- 用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive) - 元数据:Meta store
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Meta store。 - Hadoop
使用HDFS进行存储,使用MapReduce进行计算 - 驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划,对于Hive来说,就是MR/Spark。
Hive的部署
环境要求:
- JDK8
- Hadoop2.x
- Linux
- MySQL
Hive版本选择:wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.16.2.tar.gz
Hive安装步骤
1 | 解压: |
配置环境变量,建议普通用户的.bashrc文件,追加以下内容:
1 | export HIVE_HOME=/home/hadoop/app/hive |
生效环境变量文件
1 | source .bashrc |
检查是否生效
1 | which hive |
进入配置文件目录
1 | cd $HIVE_HOME/conf/ |
编译以下内容
1 |
|
保存并退出。
然后,拷贝MySQL驱动包到$HIVE_HOME/lib/下。
最后,启动Hive(需要先启动HDFS和YARN):hive
Hive常用命令
- show databases; 查看数据库
- use default; 打开默认数据库
- create database company location ‘/user/company’; 创建库并指定hdfs路径
- alter database company set dbproperties(‘creator’ = ‘vinx’); 为数据库添加额外的描述信息
- drop database if exists company cascade; 删除不为空的数据库
- show tables; 查看所在数据库的所有表
- create table student(id int, name string); 创建一张表
- desc student; 查看表结构
- desc extended student; 查看表结构详细信息
- desc formatted student; 查看表结构的格式化信息
- insert into student values(1001, “zhangsan”); 向表中插入一条数据(慎用,会跑MR程序)
- select * from student; 查询表中数据
- !clear; 清空屏幕
- quit; 退出hive
- bin/hive -e “select * from student;” 不登录hive客户端直接操作hive
- bin/hive -f /home/vinx/shell/select_stu.sql 执行HQL文件