Hadoop 数据压缩
Hadoop 数据压缩
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。通过压缩编码对Mapper或者Reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)。
压缩的好处和坏处
好处:
- 减少磁盘存储空间
- 降低IO(网络的IO和磁盘的IO)
- 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
坏处:
- 由于使用数据时,需要先将数据解压,加重CPU负荷
基本原则:
- 运算密集型的job,少用压缩
- IO密集型的job,多用压缩
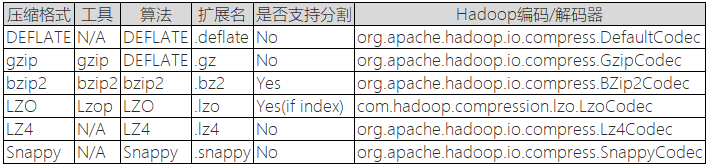
是否可分割是指,压缩后的文件是否可以再分割。可以分割的格式允许单一文件由多个Mapper程序同时读取,可以做到更好的并行化。
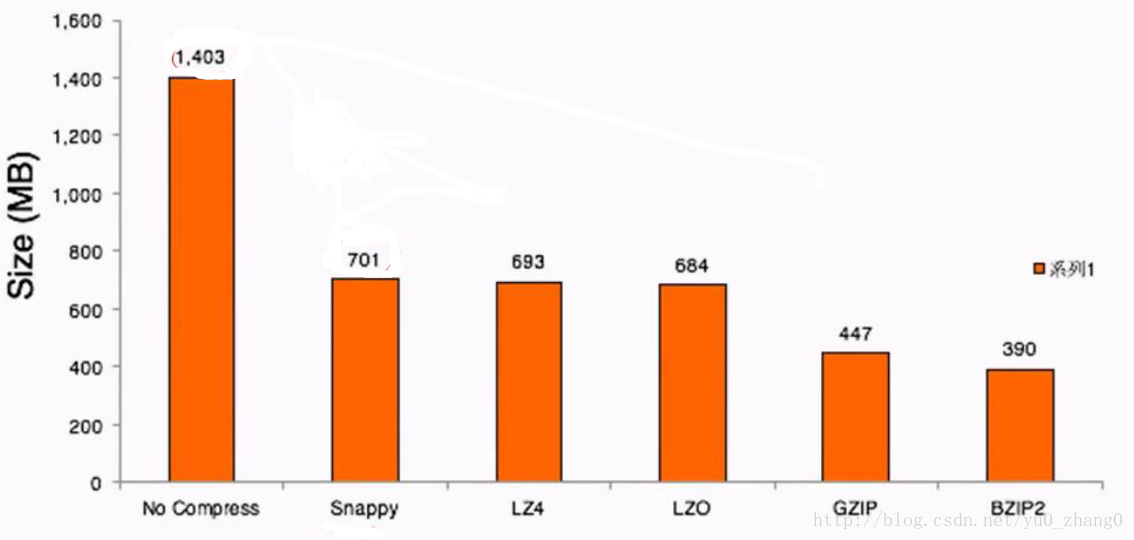
压缩比
压缩时间
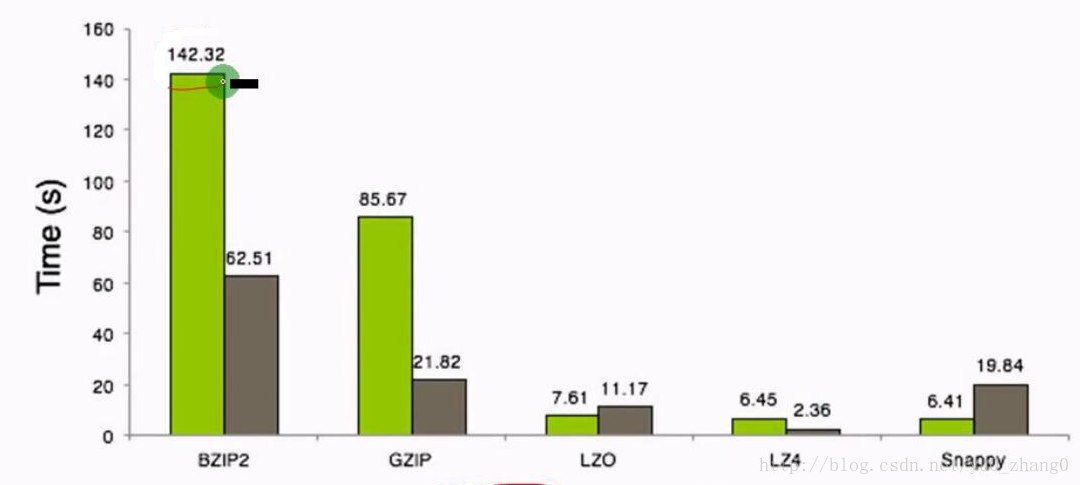
可以看出,压缩比越高,压缩时间越长,压缩比:Snappy>LZ4>LZO>GZIP>BZIP2
压缩格式的优缺点

压缩的应用场景
在Hadoop中的应用场景主要在三方面:输入,中间,输出。
整体思路:hdfs ==> map ==> shuffle ==> reduce
- Use Compressd Map Input: 从HDFS中读取文件进行MR作业,如果数据很大,可以使用压缩并且选择支持分片的压缩方式(bzip2, LZO),可以实现并行处理,提高效率,减少磁盘读取时间,同时选择合适的存储格式,例如:Sequence Files, RC, ORC等。
- Compress Intermediate Data: Map输出作为Reduce的输入,需要经过shuffle这一过程,需要把数据读取到一个环形缓冲区,然后读取到本地磁盘,所以选择压缩可以减少存储文件所占空间,提升数据传输速率。建议使用压缩速度快的压缩方式,例如:Snappy和LZO。
- Compress Reducer Output: 进行归档处理或者链接MR的工作(该作业的输出作为下个作业的输入),压缩可以减少存储文件所占空间,提升数据传输速率,如果作为归档处理,可以采用高的压缩比(Gzip, bzip2),如果作为下个作业的输入,考虑是否要分片进行选择。
压缩参数配置
要在Hadoop中启动压缩,可以配置如下参数: