Hadoop Shuffle机制
Hadoop Shuffle机制 Shuffle过程
Shuffle机制
MapReduce确保每个reduce的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入传给reduce的过程)就是Shuffle。
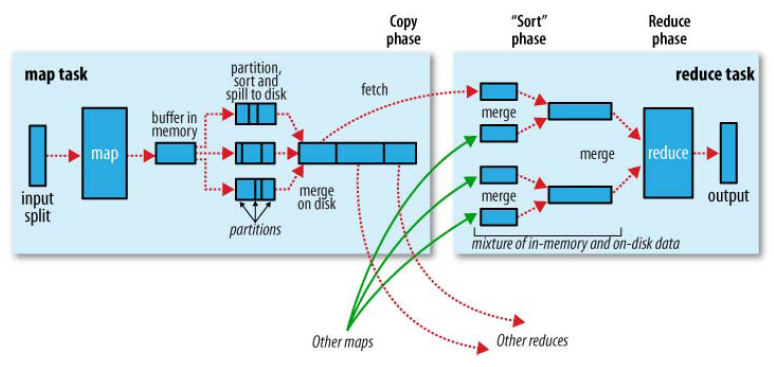
下图是Shuffle机制图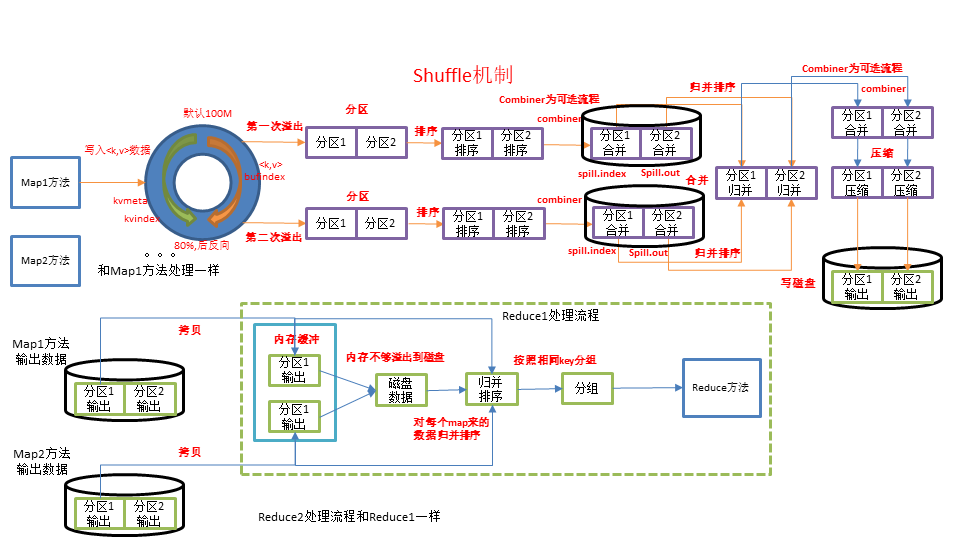
Shuffle过程
shuffle一开始就是map阶段做输出操作,map在做输出时会在内存里开启一个环形缓冲区,这个缓冲区是专门用来输出的,默认大小是100MB,并且在配置文件里为这个缓冲区设定了一个阈值,默认是0.80。同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阈值的80%的时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill(溢写)。另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作互不干扰,如果缓存区被撑爆了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作。
写入磁盘前会有个排序操作,这个是在写入磁盘操作时进行,不是在写入内存时进行的,如果我们定义了combiner函数,那么排序前还会执行combiner操作。每次spill操作也就是写入磁盘时就会写一个溢出文件,也就是说在做map输出时有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。
这个过程里还会有一个Partitioner操作,和map阶段的输入分片(Input Split)很像,一个Partitioner对应一个reduce作业,如果我们的MR操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片。
到了reduce阶段就是合并map输出文件了,Partitioner会找到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制线程,这些线程默认个数是5个,这个复制过程和map写入磁盘过程类似,也有阈值和内存大小,阈值可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算了。
上面也提到,将map的输出作为reduce的输入的过程就是shuffle(洗牌)。
那么shuffle到底是属于map阶段还是reduce阶段呢?比较公认的说法是,shuffle应该是属于reduce阶段,因为map阶段的主要任务是数据映射,而shuffle的目的是主要是为reduce阶段做准备的。
也就是说,有多少个切片,就会启动相应数量的map task进行数据处理。那么,如果需要确定map task的数量,只需要确定切片的实际数量即可。
MapReduce计算框架的不足之处
从上图可以看到,shuffle阶段中会有多次写入磁盘的操作,基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。另外,当一些查询(Hive)翻译到MapReduce任务时,往往会产生多个stage(阶段),而这些串联的stage又依赖于底层文件系统(HDFS)来存储每一个stage的输出结果,而I/O的效率往往较低,从而影响了MapReduce的运行速度。相比之下,Spark的运算结果中间不落地,而且兼容HDFS、Hive,实际应用中会以Spark替代MR作为常用的计算引擎。