Hadoop 数据切片 & MapTask并行度机制
Hadoop 数据切片 MapTask并行度
input split与map task的关系
split数量和map task数量一一对应。
下图是wordcount的流程: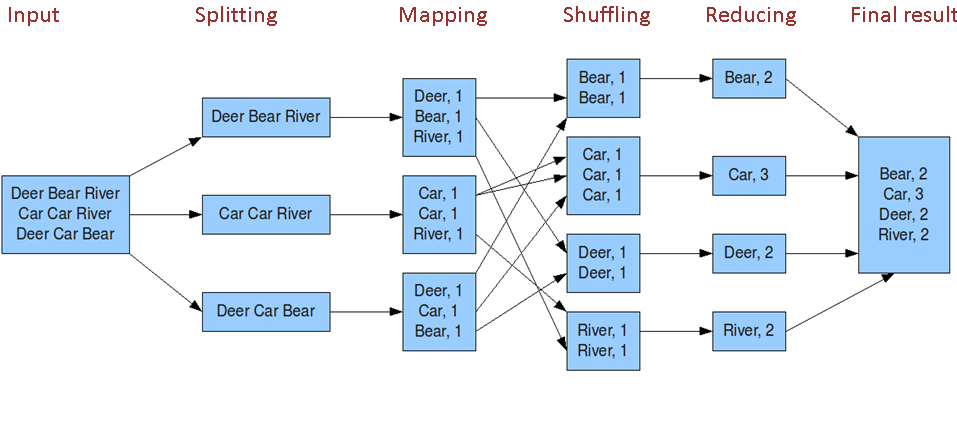
可以看到,一个job的Map阶段map task并行度(个数),由客户端提交job时的切片个数决定。
数据切片 MapTask并行度机制
假如有以下两个文件,blocksize=128M,则split和map task的关系如下图所示: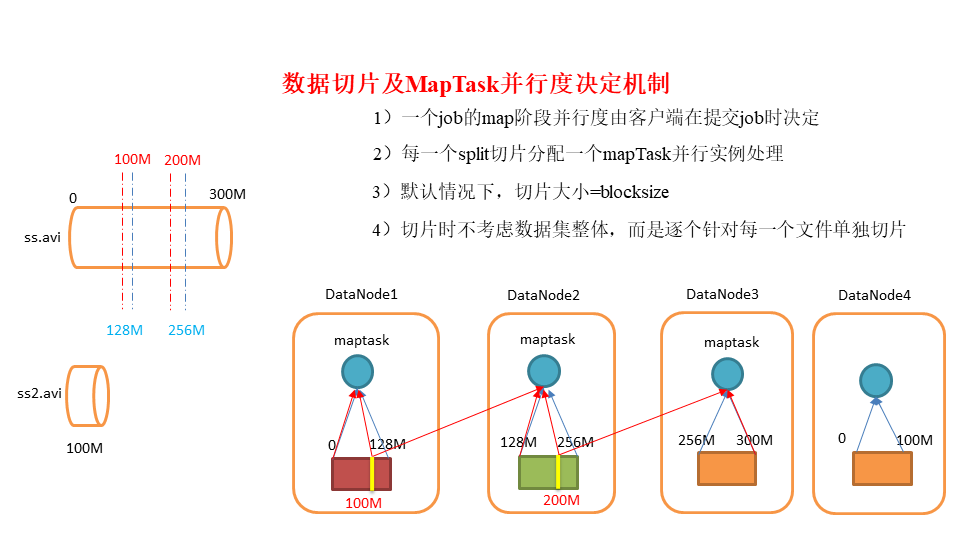
也就是说,有多少个切片,就会启动相应数量的map task进行数据处理。那么,如果需要确定map task的数量,只需要确定切片的实际数量即可。
切片机制
默认使用FileInputFormat类处理数据输入,遵循如下的切片机制:
- 按照文件的内容长度进行切片
- 切片大小,默认等于block大小
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file01.txt 320M
file02.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file01.txt.split1– 0~128
file01.txt.split2– 128~256
file01.txt.split3– 256~320
file02.txt.split1– 0~10M
那么切片的数量是否就是分块的数量+小文件的数据量呢?其实是不一定的,因为源码中还有这样一个参数:private static final double SPLIT_SLOP = 1.1,也就是还有10%的切片裕度,下面结合源码进行说明。
切片机制
整体流程:
- 找到数据存储的目录。
- 遍历处理(规划切片)目录下的每一个文件。
- 遍历第一个文件
- 获取文件大小。
- 计算切片大小,默认情况下,切片大小=blocksize。
- 每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分为一块切片。
- 将切片信息写到一个切片规划文件中。
- 整个切片的核心过程在getSplit()方法中完成。
- 数据切片只是在逻辑上对输入数据进行分片,并不会在磁盘上将其切分成分片进行存储。InputSplit只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等。
- 注意:block是HDFS物理上存储的数据,切片是对数据逻辑上的划分。
- 提交切片规划文件到YARN上,YARN上的AppMaster就可以根据切片规划文件计算开启map task个数。
总结:所以,切片的数量并不一定等于分块的数量+小文件的数据量,还要考虑大文件切分后剩余的部分是否大于块的1.1倍。